-
In February, our team won the Red Teaming category of the U.S. PETs Prize Challenge, securing a prize of 60,000 USD. In this blog post, we will provide a brief overview of the significance of Red Teaming in the field of Privacy Enhancing Technologies (PETs) research in the context of the competition. By outlining our methodology and highlighting the comprehensive objectives of a red team, we intend to showcase the essential role of Red Teaming in ensuring the development of robust and privacy-centric implementations grounded in solid theoretical foundations. We empahsize that we managed to significantly compromise all the systems we evaluated, demonstrating that even when solutions are deemed good enough to progress to the final phase of a prestigious PETs challenge, issues can still arise and persist.

-

Recent work has challenged notion that federated learning preserves data privacy by showing that various attacks can reconstruct original data from gradient updates. However, most of these works focus on the image domain. In this work, we focus on the text domain, instead, where federated learning is commonly applied. To this end, we outline some challenges posed by text data that are not present in the image domain and propose solutions to them. The obtained attack, LAMP, is substantially better quantitatively and qualitatively compared to state-of-the-art methods.
-

We provide an overview of Phoenix, our recent work on achieving neural network inference with reliability guarantees such as robustness or fairness, while simultaneously protecting client data privacy through fully-homomorphic encryption. To produce guarantees we leverage the technique of randomized smoothing, lifting its key algorithmic building blocks to the encrypted setting.
-

We investigate a well-known paradox of certified training, where most state-of-the-art methods use the loose interval-based relaxation, as using tighter convex relaxations in training often leads to worse results. We identify two previously overlooked properties of relaxations, continuity and sensitivity, which are generally unfavorable for tighter relaxations, harming the optimization procedure. We further explore possible next steps, and discuss the effect of our findings on the field.
-

The Tenth International Conference on Learning Representations (ICLR 2022) will be held virtually from April 25th through 29th. We are thrilled to share that SRI Lab will present five works at the conference, including one spotlight presentation! In this meta post you can find all relevant information about our work, including presentation times, as well as a dedicated blogpost for each work, presenting it in more detail. We look forward to meeting you at ICLR!
-

We introduce the concept of provably robust adversarial examples in deep neural networks. These are adversarial examples that are generated together with a region around them proven to be robust to a set of perturbations. We demonstrate our method, PARADE, for generating such examples in a scalable manner that uses adversarial attack algorithms to generate a candidate region which is then refined until proven robust. Our experiments show PARADE successfully finds large provably robust regions to both pixel intensity and geometric pertrubations containing up to $10^{573}$ and $10^{599}$ individual adversarial examples, respectively.
-

MN-BaB is our most recent neural network verifier that combines precise multi-neuron constraints within the Branch-and-Bound paradigm in one fully GPU-based solver. This combination of the two most successful verifier paradigms allows us to achieve state-of-the-art performance on current benchmarks and perform especially well on networks that were not trained to be easily verifiable and as a result have high natural accuracy.
-

Fair Normalizing Flows (FNF) are a new approach for encoding data into a new representation in order to ensure fairness and utility in downstream tasks. In practical cases, when we can estimate the probability density of the inputs, FNF guarantees that adversary cannot recover the sensitive attribute from the learned representations. FNF addresses limitation of existing approaches for which stronger adversaries can still recover sensitive attributes. We show that FNF can effectively balance fairness and accuracy on a variety of relevant datasets.
-

Recent work has challenged notion that federated learning preserves data privacy by showing that various attacks can reconstruct original data from gradient updates. In this post, we investigate what is the optimal reconstruction attack and we show how it connects to previously proposed attacks. Furthermore, we also show that most of the existing defenses are not effective against strong attacks. Our findings indicate that the construction of effective defenses and their evaluation remains an open problem.
-
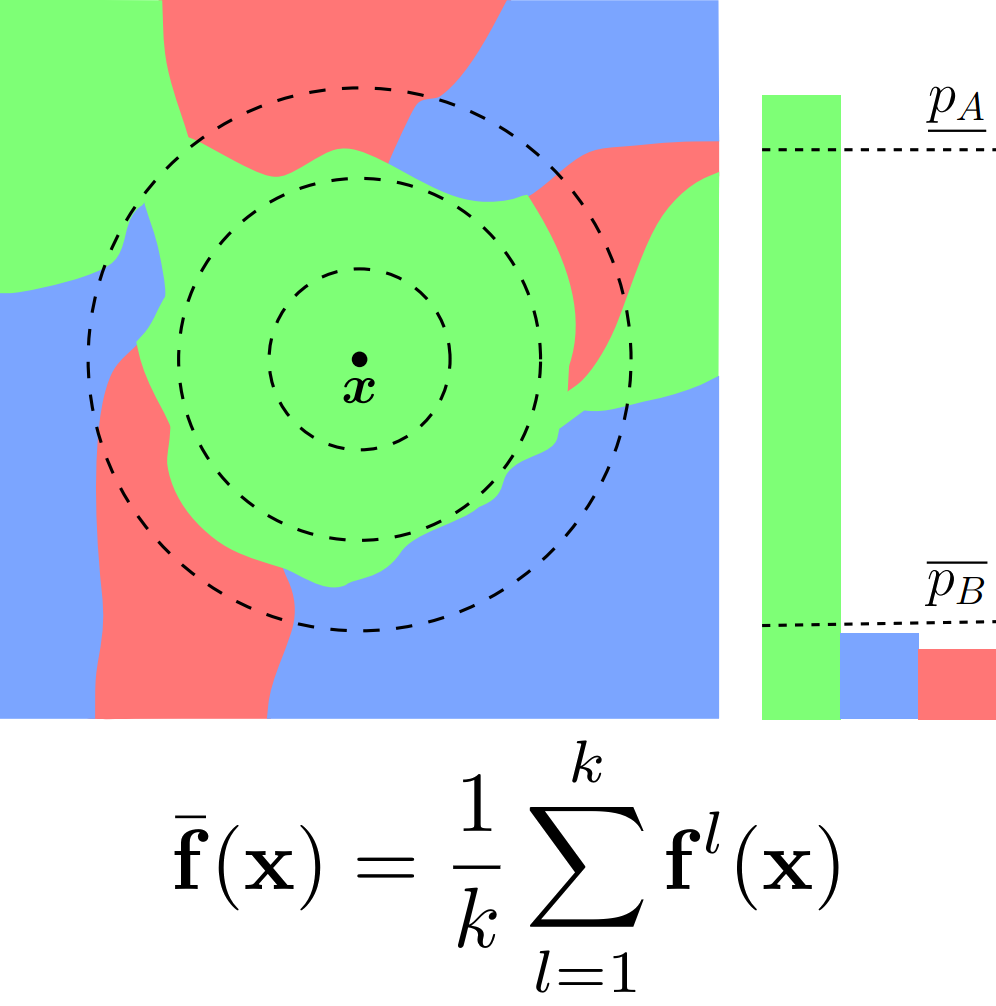
Ensembles are particularly suitable base models for constructing certifiably robust classifiers via Randomized Smoothing (RS). Here, we motivate this result theoretically and share empirical results, showing that they obtain state-of-the-art results in multiple settings. The key insight is that the reduced variance of ensembles over the perturbations introduced in RS leads to significantly more consistent classifications for a given input. This, in turn, leads to substantially increased certifiable radii for samples close to the decision boundary.